
In diesem Artikel werde ich für Nicht-Techniker beschreiben, was nötig ist, um ein 8-Euro-Gerät (ich habe den ESP32 mit einem I2S 43434 i2s-MEMS-Mikrofon verwendet) so zu trainieren, dass es einer Stimme zuhört und 12 verschiedene Wörter (Zahlen, Ja, Nein) verstehen kann. Der Artikel deckt den gesamten Zyklus ab. Um es spannender zu machen, habe ich „Transfer Learning“ hinzugefügt, um ein Problem namens „Overfitting“ zu vermeiden, das bei vielen Modellen häufig auftritt. Ich werde auch einige wichtige Erkenntnisse zum maschinellen Lernen (ML) teilen und darüber berichten, was ich gelernt habe.
Am Ende hast du vielleicht ein besseres Gefühl dafür, was ML bedeutet … und hoffentlich auch, warum es Spaß macht, damit herumzuspielen.
Und nicht zu vergessen: Dir wird vielleicht klar, dass dies *KEINE* künstliche Intelligenz ist, sondern nur ein cleverer Algorithmus, der versucht, ein mathematisches Problem zu lösen. Wenn er gut gemacht ist, versteht er die Zahlen 🙂
Die Ergebnisse meiner Übung kannst du dir hier ansehen:
Motivation – Demokratisierung von künstlicher Intelligenz / Machine Learning
Wenn du im Bereich Data & Analytics arbeitest, kommst du zwangsläufig mit maschinellem Lernen in Berührung: Es ist überall. Während eines Hackathons zum Thema ML hatte ich die Gelegenheit, mich intensiv mit Datenanalyseplattformen wie Dataiku, DataRobot, Domino und Matlab auseinanderzusetzen – die dich über den gesamten Zyklus hinweg unterstützen, von der Datentransformation über die Merkmalsgenerierung und Modellentwicklung bis hin zur Bereitstellung und Operationalisierung. Wir haben den Hackathon schließlich mit Dataiku durchgeführt (hey, ich bin jetzt zertifizierter Dataiku Core Designer). Es ist ein Aha-Erlebnis, wenn man erst einmal versteht, wie einfach es ist, ML im täglichen Geschäftsbetrieb einzusetzen – von der Erkennung von Ausreißern (seltsame Zahlen finden) bis hin zur Zeitreihenprognose (Umsatzvorhersagen).
Neue Tools und Plattformen wie Google (TensorFlow) und Dataiku führen im Grunde zu einer Demokratisierung von ML: Sie nehmen einem die Last ab, die Mathematik verstehen zu müssen, und lassen sich nahtlos in die bestehende IT-Landschaft integrieren.
Mit einer Umgebung ohne Programmieraufwand stärkt das auch das Geschäft und macht es für jeden zugänglich….
Ich weiß gar nicht mehr, wie ich auf Edge Impulse gestoßen bin – kann es wirklich sein, dass es so einfach ist, einen günstigen Mikroprozessor (wie einen ESP32 für 8 €) so zu trainieren, dass er auf meine Sprachbefehle hört? Offensichtlich ist das möglich und wirklich einfach; schau dir dieses Video an, du wirst viel lernen. Edge Impulse wurde für Softwareentwickler, Ingenieure und Fachexperten entwickelt, um reale Probleme mithilfe von Machine Learning auf Edge-Geräten zu lösen, ohne einen Doktortitel in Machine Learning zu haben.
Also… was habe ich eigentlich gemacht?
Google TensorFlow ist eine kostenlose Open-Source-Bibliothek für maschinelles Lernen, mit Schwerpunkt auf Training und Inferenz (wenn du das Netzwerk tatsächlich ausführst, um etwas Nützliches zu tun). Normalerweise (vor allem beim Training) brauchst du viel Rechenleistung, um das Modell zu trainieren oder auszuführen. ABER – es gibt eine Variante von TensorFlow – eine Light-Version namens „TensorFlow Lite for Microcontroller“, die dafür ausgelegt ist, auf eingebetteten Geräten (wie dem ESP32) mit nur wenigen Kilobyte Speicher zu laufen. Das ist tatsächlich eine Revolution, denn so kann ML aus der Cloud auf jedes beliebige Gerät übertragen werden!
Schauen wir uns mal an, wie das funktioniert, und ob wir es mit meiner Stimme zum Laufen bringen können!
Dem Standardablauf des maschinellen Lernens folgend, hier ein grober Überblick über meinen Prozess (könnte kürzer sein, aber ich möchte die volle Kontrolle darüber haben – und lernen)
- Trainingsdaten aufnehmen und an den lokalen Linux-PC senden – Roh-Audiodateien mit 1 Minute, in denen ich „eins, eins, eins…“ wiederhole 🙂
- Die Daten mit Python-Skripten bereinigen (insbesondere die Datei in gleich lange Soundclips aufteilen)
- Zusatzübung (erkläre ich später): Parameter eines vortrainierten Modells verwenden (Kasten: Transfer Learning)
- Das Folgende läuft auf EdgeImpulse (Cloud):
- Lade die Trainingsdaten hoch
- Feature-Generierung – Bereite die Features (also die Daten, die tatsächlich „in das Modell“ geladen werden) aus den Trainingsdaten vor
- Trainiere das Modell und überprüfe die Leistung
- Stelle das trainierte Modell bereit (als Arduino-C-Code), bereit zur Ausführung auf ESP32 – was ich für eine wirklich tolle Funktion von EdgeImpulse halte
- Erstelle das Image/Programm in „C“ und lade es auf den ESP hoch
- Viel Spaß damit…
Ok… ehrlich gesagt… es muss klar sein, dass das ein Kreislauf ist… und ich habe diesen Kreislauf viele Male durchlaufen.
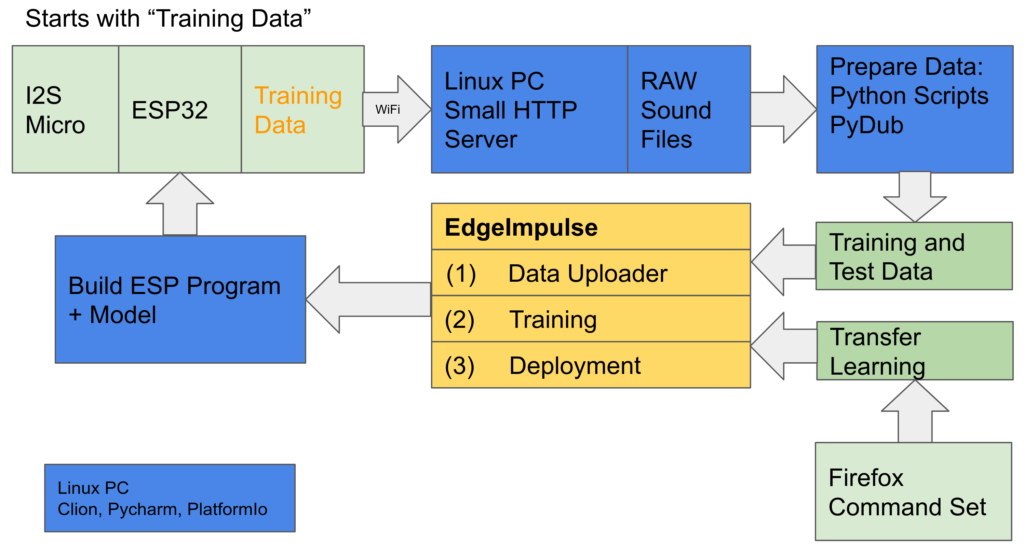
1 – Trainingsdaten beschaffen
Trainingsdaten aufzeichnen (je mehr, desto besser) – in meinem Fall meine Stimme (die Zahlen von null bis zehn, Ja und Nein) als .wav-Dateien mit einem ESP32und einem I2S-Mikrofon zur Aufnahme (I2S ist eine 3-Draht-Schnittstelle für Ton). EdgeImpulse bietet einen Daten-Forwarder, mit dem du die Daten direkt in die Cloud hochladen kannst, damit sie für das Training verwendet werden können.
Ich wollte meine Sprachdaten jedoch vor dem Hochladen bearbeiten oder anpassen können, daher war der Ansatz ein anderer: Ich habe die Stimme auf dem ESP32 aufgenommen und sie per WLAN an meinen Desktop-PC gesendet. So konnte ich die Daten vorverarbeiten: Ich habe Python und PyDub verwendet, um die Datei anhand der Stilleerkennung zu teilen, sodass jedes Snippet genau eine Zahl enthält. Jedes Ton-Snippet wurde auf eine Länge von 700 ms (0,7 Sekunden) angepasst – so lange brauche ich im Durchschnitt, um eine Zahl auszusprechen. Das Skript filterte außerdem zu lange oder zu kurze Snippets heraus (gelb und blau) oder fügte zusätzliches Rauschen hinzu, wenn das Snippet zu kurz war (grün). Meine Samples waren 16000 Hz, 16-Bit-PCM mit Vorzeichen, Little-Endian.
Lektion 1: Trainingsdaten müssen wirklich korrekt und gut beschriftet sein, der Kontext der Daten muss verstanden werden. Sie müssen eine große Vielfalt abdecken. Sei nicht zu optimistisch: Was das Modell während des Trainings nicht sieht, wird es mit geringerer Wahrscheinlichkeit erkennen.
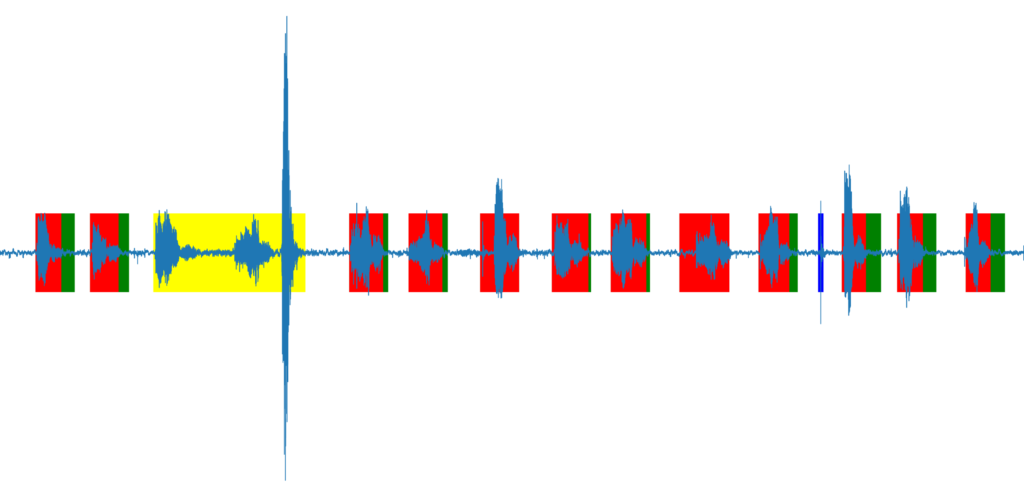
2 – Merkmalsgenerierung
Das war die schwierigste Lektion – der komplexeste Teil ist nicht das Trainieren des Modells, sondern die Vorbereitung der Merkmale. Das Merkmal ist im Grunde die Daten, die direkt in das Modell eingegeben werden – als Satz numerischer Werte konstanter Länge und der Beschriftung. Die Merkmale, die du generiert hast, müssen zum Modell passen; es ist ein bisschen so, als würde man den Algorithmus bereits auf die Lösung hinweisen – man serviert dem Modell die Daten auf dem Silbertablett. Für die Spracherkennung empfiehlt es sich, ein CNN (Convolutional Neural Network) zu verwenden.
Aber dieses Netzwerk benötigt ein Bild als Eingabe – wie also ein Bild aus einer WAV-Datei (.wav) gewinnen? Nun, man erstellt ein Bild aus der WAV-Datei. Wie du siehst, habe ich das oben bereits getan – so konnte ich diese Bilder verwenden und die Binärdaten (Farbcodes) dieses Bildes in das Modell laden. Das Modell würde die Merkmale des Bildes lernen und die richtige Zahl finden (…theoretisch). Aber denk an die „goldene Platte“ – es gibt eine viel bessere Methode, um Klang darzustellen – das nennt man ein MEL-Diagramm.
Du kannst es googeln, aber kurz gesagt: Man betrachtet nicht die Wellenform deiner Stimme, sondern die Frequenz (y-Achse) deiner Stimme über die Zeit (x-Achse) mithilfe einer Fourier-Transformation. Es heißt MEL-Diagramm, weil die Frequenz entsprechend der Empfindlichkeit unserer Ohren skaliert ist. Wenn du die folgenden Bilder vergleichst, kannst du vielleicht schon den Zusammenhang zwischen beiden erkennen und dass das zweite (MEL) leichter zu interpretieren ist.
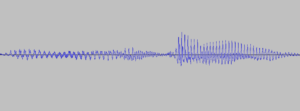
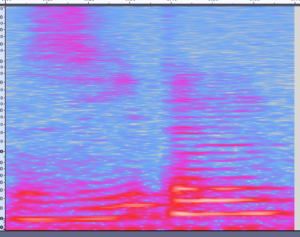
Der knifflige Teil bei der Erzeugung der Merkmale ist es, die richtigen Parameter zu finden. Das obige Bild hat eine hohe Auflösung, das heißt, es hat viele Pixel. Also – zu viele Pixel für ein kleines ESP32-Edge-Gerät.
Lösung: Es gibt einige Parameter in der MEL-Funktion, die die Anzahl der Frequenzbänder reduzieren (weniger Punkte auf der y-Achse) oder die Abtastfrequenz erhöhen (weniger Messpunkte über die Zeit – weniger Punkte auf der x-Achse). Du musst also ein wenig mit den Parametern der Fourier-Transformation herumspielen und ein Gefühl dafür entwickeln (oder dich auf die Voreinstellung verlassen). Dies wurde in Edge Impulse durchgeführt, unten siehst du einen Screenshot.
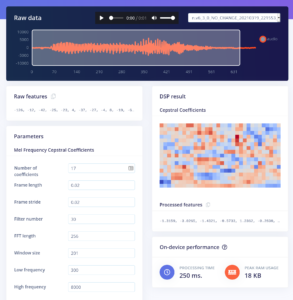
Ein bisschen Mathematik – um dir zu zeigen, wie das funktioniert: Wir nehmen mit 16 kHz ab, das bedeutet 16.000 Messungen (Werte) pro Sekunde. Das ist zu viel für unser ESP, daher wird die Frequenz in Blöcken von 20 ms gemittelt, was zu 32 Werten pro 650 ms führt (ich habe 30 genommen). Für die Fourier-Transformation haben wir 17 Koeffizienten ausgewählt (das bedeutet, dass 17 Werte die Frequenz beschreiben), also erhalten wir alle 20 ms 17 Werte (das entspricht einem Pixel auf der y-Achse im obigen Bild). 17*30=510 – so einfach ist das. Unser Modell muss 510 Datenpunkte pro 650 ms Ton verarbeiten. Wie du siehst: Feature-Design = Datenreduktion, bei gleichzeitiger Beibehaltung der wesentlichen Informationen.
Jeder Datenpunkt stellt eine Gleitkommazahl dar, was für Edge-Geräte zu schwierig ist. Dank TensorFlow Light ist es möglich, diese Gleitkommazahlen in 8-Bit-Ganzzahlen umzuwandeln – etwas, womit kleine Geräte sehr gut zurechtkommen.
Also… nach all dieser Arbeit haben wir viele, viele Wave-Dateien, die in Merkmale von 510 Byte umgewandelt wurden und bereit sind, in unser Modell zum Trainieren geladen zu werden
2. Modellentwurf und Training
Wie bereits bei der Bildverarbeitung erwähnt, ist ein CNN (Convolutional Neural Network) eine gute Wahl. Suche bei Google nach „cnn ml tutorial“, um eine wirklich gute Erklärung zu finden. Ich gebe dir meine persönliche, nicht wissenschaftliche und nicht beglaubigte Version – es ist meine persönliche Sichtweise, die mir geholfen hat, das Ganze zu verstehen:
Das Modell
Ein CNN-Netzwerk verarbeitet das Bild in Schritten (Schichten), wobei jede Schicht Merkmale aus diesem Bild extrahiert und die Größe des Bildes reduziert (schöne Erklärung). Am Ende wird die Größe so weit reduziert, dass sie deinen Ausgangskanälen entspricht; in meinem Beispiel wurde sie also von 510 Werten auf 12 Kanäle reduziert (Null bis Neun + Ja und Nein).
Unten siehst du das Netzwerk, das ich verwendet habe; es ist in „KERAS“ beschrieben – einer Sprache zum Definieren und Ausführen von ML-Modellen. Schauen wir es uns Zeile für Zeile an:
model = Sequential()
model.add(Reshape((int(input_length / 17), 17), input_shape=(input_length, )))
model.add(Conv1D(14, kernel_size=3, activation='relu', padding='same',trainable=True))
model.add(MaxPooling1D(pool_size=2, strides=2, padding='same'))
model.add(Conv1D(25, kernel_size=3, activation='relu', padding='same',trainable=True))
model.add(MaxPooling1D(pool_size=2, strides=2, padding='same'))
model.add(Flatten())
model.add(Dense(classes, activation='softmax', name='y_pred'))Was bedeuten diese Zeilen eigentlich – ohne tief in Keras einzutauchen, aber ich denke, du verstehst das Konzept trotzdem:
- „Reshape“ – dir fällt die „17“ auf – die Anzahl der Frequenzbins; natürlich musst du dem Netzwerk die Dimension deines Bildes mitteilen.
- „Conv1d“ – die erste Ebene zur Extraktion von Merkmalen
- „MaxPooling“ – die Größe des Bildes reduzieren
- „Conv1d“ – erneute Reduzierung der Merkmalsebene
- Flatten und Dense: Reduziere den Wert auf die Ausgabe von 12 Labels
Das Training
Jede Schicht dieses Modells verfügt über zahlreiche Parameter (z. B. definiert durch „14“ und „25“) und Filter (kernel_size, pool_size), die beschreiben, wie die Merkmale extrahiert werden.
Beim Training fütterst du also alle unsere Beispielmerkmale in das Modell ein und spielst mit den Parametern herum, bis die Vorhersage (letzte Schicht) dir die richtigen Werte liefert. Du musst herumprobieren – das Training „immer und immer wieder“ durchlaufen, bis dein Modell eine gute Genauigkeit erreicht, z. B. wenn es 98 % deiner Beispieldaten korrekt vorhersagen kann.
Maschinelles Lernen (zum besseren Verständnis): Das ist mehr oder weniger dasselbe wie das Lösen einer Gleichung. Wenn die Prognoseergebnisse gut genug sind, hast du den Fehler dieser Gleichung durch Training oder das Herumprobieren mit den Modellparametern minimiert.
Die verschiedenen Schichten deines Modells filtern die Merkmale deiner Eingabewerte bis hinunter zur Ausgabeschicht, wo das wahrscheinlichste Ergebnis angezeigt wird (um ein CNN-Modell zu beschreiben; andere Modelle funktionieren nach einem anderen Prinzip – aber es handelt sich dennoch um eine Gleichung).
Ich würde das nicht unbedingt als „Künstliche Intelligenz“ bezeichnen. Fairerweise muss man sagen, dass es andere Arten des maschinellen Lernens gibt, bei denen man verschiedene Algorithmen gegeneinander antreten lässt – damit sie sich selbst verbessern – oder beim verstärkenden Lernen, bei dem „intelligente Agenten“ durch eine Belohnung motiviert werden, ein Problem zu lösen. Letztendlich kann all das von der biologischen Evolution inspiriert sein – vielleicht haben wir also in Zukunft „Intelligenz“.
Überanpassung – die große Herausforderung beim Training
Beim Training werden verschiedene Arten von Daten verwendet:
- Trainingsdaten: Diese Daten werden verwendet, um die Parameter des Modells zu bestimmen, indem der Fehler gegenüber dem Ergebnis minimiert wird
- Validierungsdaten: Diese Daten werden während des Trainings verwendet, um zu sehen, wie gut das Modell funktioniert, und um weitere Feinabstimmungen vorzunehmen
- Testdaten: Neue Daten, die das Modell noch nie „gesehen“ hat – um seine Leistung in der realen Welt zu testen
- Produktionsdaten (das ist meine Erfindung): Die Daten, die das Modell tatsächlich erhält, wenn es auf dem Edge-Gerät installiert ist – „echte Live-Daten“. Ich musste lernen, dass es immer einen kleinen Unterschied zwischen den Daten gibt; in der Realität schneidet das Modell immer etwas schlechter ab als im Training.
Stell dir vor: Du hast ein Modell mit 100 Parametern, das trainiert werden muss, und du hast 10 Sätze Trainingsdaten mit jeweils 10 Merkmalen. Dein Modell hat 100 Variablen (Parameter), um 100 (10*10) Trainingskombinationen zu speichern. In diesem Szenario muss dein Modell nicht unbedingt lernen – es muss sich lediglich merken und 1 Eingabekombination = 1 Ausgabe zuordnen. Oder das untenstehende Modell, das versucht, zwischen Blau und Rot zu unterscheiden: Es passt zu 100 % zu den Trainingsdaten, aber du kannst dir vorstellen, dass es bei echten Produktionsdaten nicht gut laufen wird.
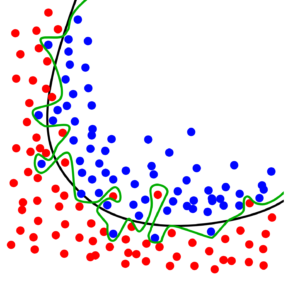
Überanpassung ist ein großes Risiko, weil du nicht in dein Modell hineinschauen kannst – und du kannst nicht sicher sein, welche Merkmale das Modell zum Filtern verwendet, nur die Farbe dieses einen Pixels? Ein weiteres Risiko ist sehr ähnlich – du denkst, dein Modell verwendet die richtigen Merkmale, aber es achtet auf etwas ganz anderes. (z. B. ein Modell, das Gesichter erkennen soll und stattdessen nur Brillen erkennt (aufgrund unausgewogener Trainingsdaten). Bei meinen Sprachdaten habe ich festgestellt, dass die Länge des Tonaufnahmeschnipsels als wichtig angesehen wurde – wenn man also langsam spricht, funktioniert es nicht.
Es gibt einige Methoden, um das zu umgehen – aber (stell dir Hunderte von Datenquellen für Finanzprognosen vor, auf die du dich verlassen willst) – wie kannst du wirklich sicher sein, dass dein Modell auf die richtigen Dinge achtet? Ich glaube, es ist wie in der Statistik: Vertraue nur deinen eigenen Daten oder dem Modell, das du kennst (zumindest den Daten, mit denen es trainiert wurde) 🙂
Überanpassung – wie lässt sich das verhindern?
Auch dieser Teil ist kein wissenschaftlicher Vortrag – nur ein paar Ideen, die ich in meiner Lösung umgesetzt habe. Wichtig zu erwähnen ist, dass du das bei der Arbeit mit EdgeImpulse einfach überspringen und dich an die vorgeschlagenen Werte halten kannst. Aber mal ehrlich, das ist zu einfach. Um das Folgende zu tun, habe ich das Modell mit Python auf meinem lokalen PC neu erstellt (der gesamte Code ist unten auf GitHub aufgeführt)
- Nimm eine Menge Trainingsdaten (das ist wirklich die einfachste und effektivste Methode)
- Füge Rauschen und Varianz zu deinen Trainingsdaten hinzu (z. B. verschiebe einige Schnipsel, mache sie kürzer, länger; bei Bildern kannst du sie vertauschen, drehen, aufhellen …)
- Überprüfe die Größe deines Modells und mache es so klein wie möglich (ich habe mit Hyperparametern gearbeitet), bis mein Modell eine gute Größe hatte; ein kleines Modell mit begrenzten Parametern läuft auch viel schneller auf dem Edge-Gerät, und das Timing ist entscheidend
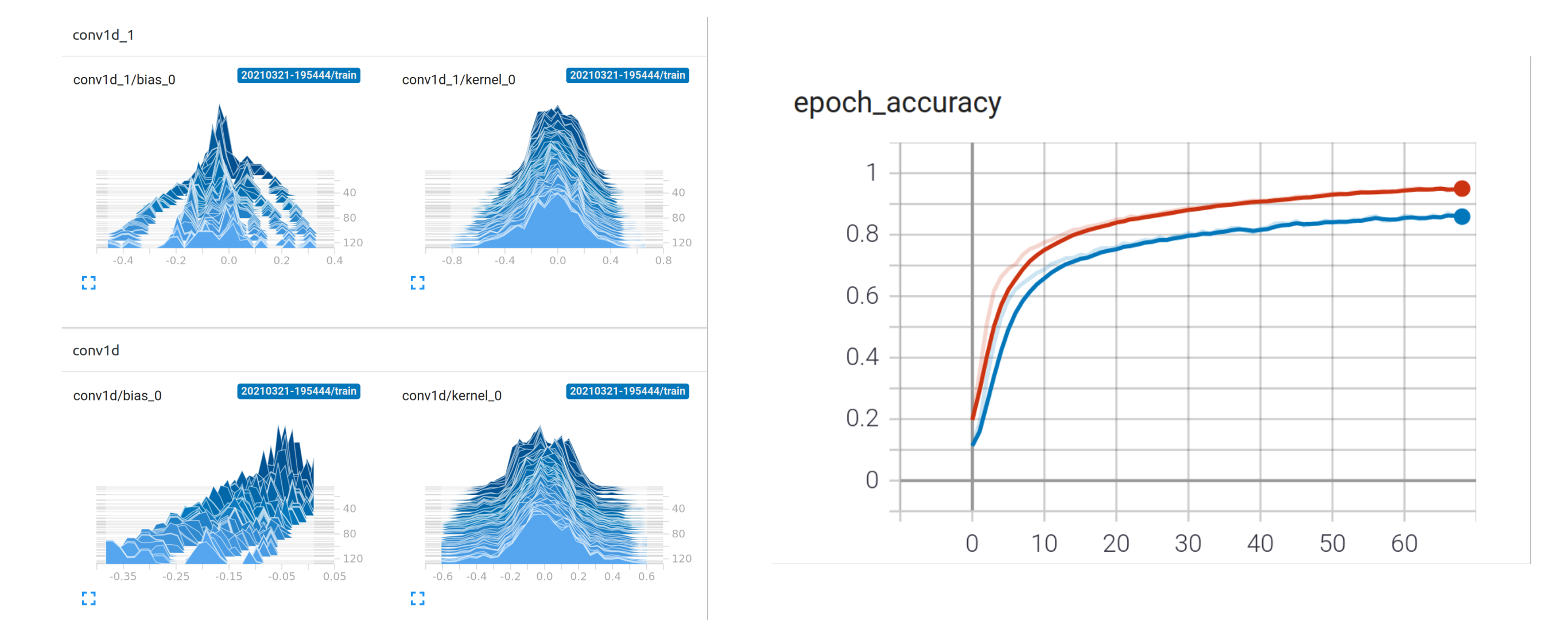
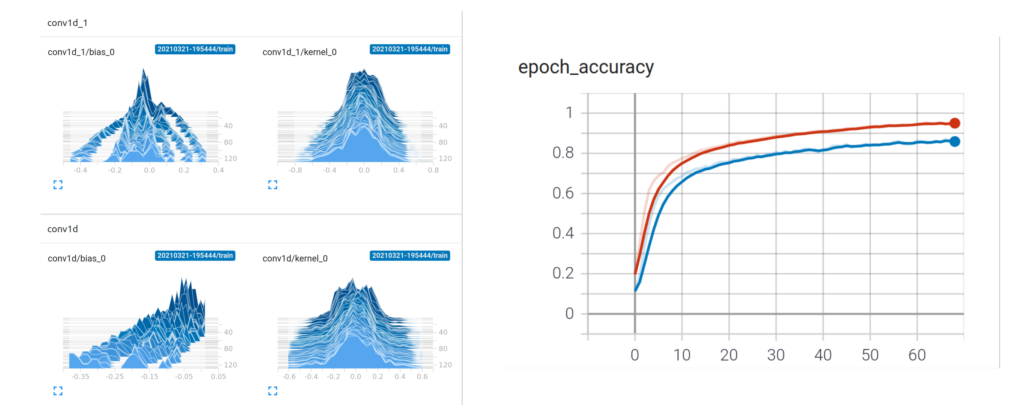
- Zu guter Letzt – schau dir das Modell mit Tensorboard an: Die vier kleinen Bilder unten zeigen die Veränderung der Modellvariablen der verschiedenen Schichten (x/y-Achsen) im Laufe der Zeit während des Trainings (Epochen). Zu Beginn (hinten auf der z-Achse) sind alle Trainingsvariablen gleichmäßig verteilt (mit Zufallswerten initialisiert) – mit der Zeit siehst du, wie sie sich ausbreiten und unterschiedliche Werte annehmen – das Modell lernt. An der „epoch_accuracy“ siehst du, wie das Modell mit der Zeit besser wird (1 = 100 % korrekt)
Transferlernen
Eine andere Art von Überanpassung kann ebenfalls auftreten, wenn ich das System nur mit meiner eigenen Stimme trainiere – es könnte sich an Merkmale meiner Stimme gewöhnen, von denen ich vielleicht nicht einmal träume, wie Atmen, Pausen machen oder eine Erkältung – das würde natürlich die Robustheit meines Modells verringern.
Mein Ansatz war daher, das Modell zunächst mit einem breiteren Sprachsatz zu trainieren (viele Zahlen, gesprochen von verschiedenen Personen – ich habe den „https://commonvoice.mozilla.org/en“ verwendet). Nach mehreren Trainingsrunden und sobald sich die Parameter eingependelt haben (das heißt, die Modellparameter haben sich irgendwo stabilisiert und das Modell funktioniert), würde ich dieses vortrainierte Modell übertragen und eine zweite Trainingsrunde nur mit meiner Stimme fortsetzen. In dieser zweiten Runde habe ich eine sehr kleine Schrittweite verwendet – das Modell ändert sich also nur in winzigen Schritten, wobei die Kernmerkmale des ursprünglichen Trainings erhalten bleiben.
Es gibt auch andere Möglichkeiten, dies zu tun, z. B. einfach meine eigene Sprachaufnahme mit einem gemischteren Sprachsatz mehrerer Sprecher zu kombinieren und alles in einer gemeinsamen Trainingsrunde zu verarbeiten. Ich gehe davon aus, dass ich viele Sprachbeispiele von mir benötigen würde, um genügend Einfluss zu erzielen und das Modell auf meine Stimme „abzustimmen“. Der Vorteil des von mir verwendeten „Transfer Learning“-Szenarios besteht also darin, dass ich in der zweiten Trainingsrunde über die Schrittweite und die Trainingsrunde genau steuern kann, wie stark meine „Stimme“ im Vergleich zum breiteren Datensatz ins Gewicht fällt. Ich glaube, man nennt das „Transfer Learning“, da ich das Wissen eines eher generischen Modells auf ein spezifischeres Modell übertrage.
So geht’s mit EdgeImpulse
Um das mit EdgeImpulse zu machen, habe ich Modell-1 mit „commonvoice“ auf meinem lokalen Laptop trainiert, bis ich vernünftige Ergebnisse bekam (erwarte keine gute Leistung von einem ESP32 mit so einem begrenzten neuronalen Netzwerk). Sobald es fertig war, habe ich das trainierte Modell-1 (exportiert über TensorFlow in einem speziellen „h5“-Format, das alle Modellparameter enthält) genommen und es als „Startgewichte“ in das EdgeImpulse-Modell-2 eingefügt. Das Training und die Bereitstellung folgen dem normalen Ablauf.
# Done on the local PC with the trained model-1 from Commonvoice-Mozilla
rd= open(SOURCE_H5_MODEL,'rb').read()
rd_64 = base64.b64encode(rd)
h5_model_str=rd_64.decode("UTF-8")
# Done on EdgeImpulse on the classifier page (setting to "Expert Mode")to train model-2
import tensorflow as tf
import base64
import h5py
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, InputLayer, Dropout, Conv1D, Conv2D, Flatten, Reshape, MaxPooling1D, MaxPooling2D, BatchNormalization
from tensorflow.keras.optimizers import Adam
sys.path.append('./resources/libraries')
import ei_tensorflow.training
model_weights_str='iUhERg0KGgoAAAAAAAgIAAQAEAAAAAAAAAAAAAAAAAD//////////5iUAAAAAAA...... # <-------- here I pasted the content of the h5_model_str
# from utf-8 back to binary
model_weights_b64=model_weights_str.encode('utf-8')
model_weights=base64.b64decode(model_weights_b64)
f = open("model_v3.h5", "wb")
f. write(model_weights)
f.close()
# model architecture
model = Sequential()
model.add(Reshape((int(input_length / 17), 17), input_shape=(input_length, )))
model.add(Conv1D(14, kernel_size=3, activation='relu', padding='same',trainable=True))
model.add(MaxPooling1D(pool_size=2, strides=2, padding='same'))
model.add(Dropout(0.25))
model.add(Conv1D(25, kernel_size=3, activation='relu', padding='same',trainable=True))
model.add(MaxPooling1D(pool_size=2, strides=2, padding='same'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(classes, activation='softmax', name='y_pred'))
model.load_weights('model_v3.h5') # here the parameter of model-1 are loaded as initializing values for model-2Ein paar abschließende Worte
Ehrlich gesagt – das war eine knifflige Aufgabe, dem ESP32 insgesamt 12 Wörter beizubringen – vor allem, weil im Deutschen viele Zahlen sehr ähnlich klingen: „eins, zwei, drei“ oder „null, neun, nein“. Und das einzige, womit ich das geschafft habe, war, das Training wirklich auf meine Stimme zu beschränken, sodass es wirklich nur auf mich hört (was auch irgendwie cool ist). Außerdem muss es still sein – ich habe keinen Datensatz für „unbekannte Geräusche“ eingebaut, um die Klassifizierung „unbekannter“ Töne zu verbessern.
Es waren viele Versuche nötig, um die optimale Modellgröße (Anzahl der Schichten, Neuronen) zu ermitteln. Außerdem ist das Timing extrem wichtig – wie lang ist der aufgenommene Ausschnitt? Ist er lang, kann ich zwar sehr langsam sprechen, aber der ESP32 muss mehr Daten verarbeiten – und läuft ins Timeout.
Ein absolut fantastisches Bonbon von EdgeImpulse ist der Quellcode des „Inferencing SDK“: DSP-Python-Skripte von EdgeImpulse als Python-Skript. Damit kannst du das Modell auf deinem lokalen PC mit Python trainieren und auf den ESP32 übertragen – wobei die gleiche Merkmalserkennung wie bei C läuft. Die in Python erstellten Merkmale sehen genau so aus wie auf dem ESP32 (ich habe es überprüft).
Ich habe keine Lust, meine Python-Skriptsammlung zu veröffentlichen – sie ist wirklich etwas chaotisch und mit der Zeit immer größer geworden. Aber du kannst das Ergebnis in Aktion sehen mit meinem sprachgesteuerten eInk-Wecker: Goodwatch