„Kann ich nicht einfach ChatGPT fragen?“ Das ist die Frage, die dir heute innerhalb von zwei Minuten nach Beginn eines jeden Programmierkurses mit Kindern gestellt wird. Die ehrliche Antwort lautet: Ja, das kannst du – aber wenn das zur Gewohnheit wird, überspringst du den Teil, der eigentlich wichtig ist. Genau diese Spannung ist der Grund, warum ich PyLearn entwickelt habe, eine browserbasierte Python-Lernplattform. Und eigentlich geht es gar nicht um Python.
Für wen ist das gedacht? Für Lehrer mit einer Vorliebe fürs Programmieren, Entwickler, die gelegentlich unterrichten, oder jeden, der einen Programmierclub leitet und sich gefragt hat, wie man konstruktiv mit der KI-Frage umgeht – anstatt sie zu ignorieren oder zu verbieten.
>>>> Weitere Informationen, eine detaillierte Beschreibung und das Kurskonzept findest du hier: PyLearn im Überblick – Programmier- und KI-Kompetenz für junge Lernende
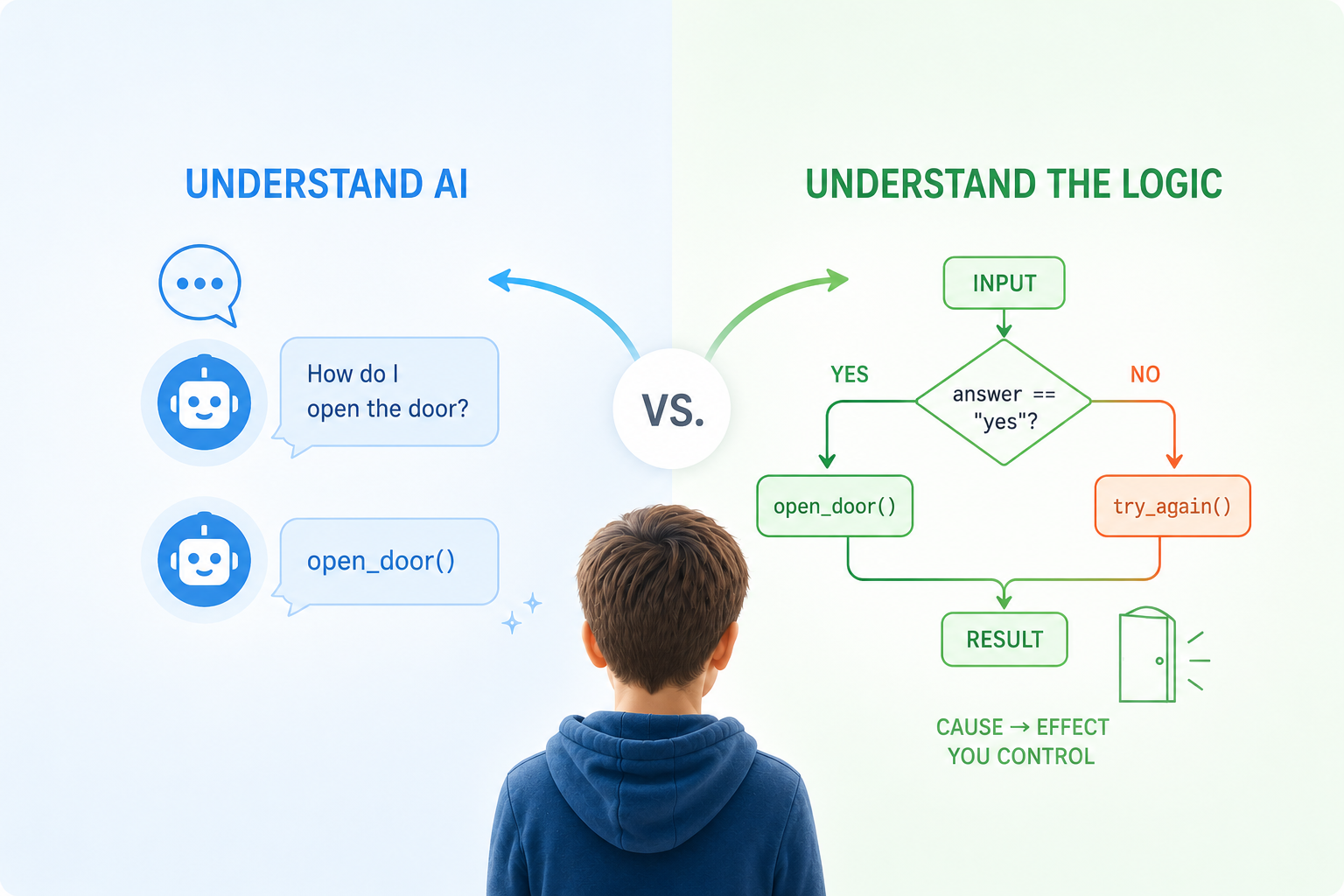
Zwei Denkmodelle, die getrennt bleiben müssen
Programmieren ist deterministisch. Ein Schüler schreibt if score > 80: print("Top"), und der Computer tut genau das – jedes Mal, ohne Interpretation, ohne Meinung. Wenn etwas nicht funktioniert, gibt es immer einen nachvollziehbaren Grund, und der Schüler kann ihn finden.
KI ist das Gegenteil. Sie erzeugt plausible Ergebnisse auf der Grundlage von Mustern – oft nützlich, gelegentlich falsch, und zwar auf eine Weise, die völlig überzeugend wirkt. Kindern den Umgang mit KI-Tools beizubringen, ohne ihnen zuvor diesen Unterschied zu vermitteln, ist so, als würde man jemandem das Autofahren beibringen und ihm dabei sagen, dass der Autopilot alles regelt.
Das eigentliche Lernziel von PyLearn ist es, Kindern beide Aspekte im Kontrast zueinander durch eigene Handgriffe näherzubringen.
Wie sich der Lernfortschritt für einen Schüler anfühlt
Die Schüler sehen nie einen leeren Editor – jede Übung beginnt mit funktionierendem Code, den sie modifizieren. Die erste Sitzung ist reines Python, keine KI, keine Abkürzungen. Die Kinder sagen voraus, was ein kleines Programm tun wird, bevor sie es ausführen, bauen das mentale Modell auf, dass Ursache Wirkung erzeugt, und beheben ihre eigenen Fehler. Die KI ist noch nicht einmal sichtbar.
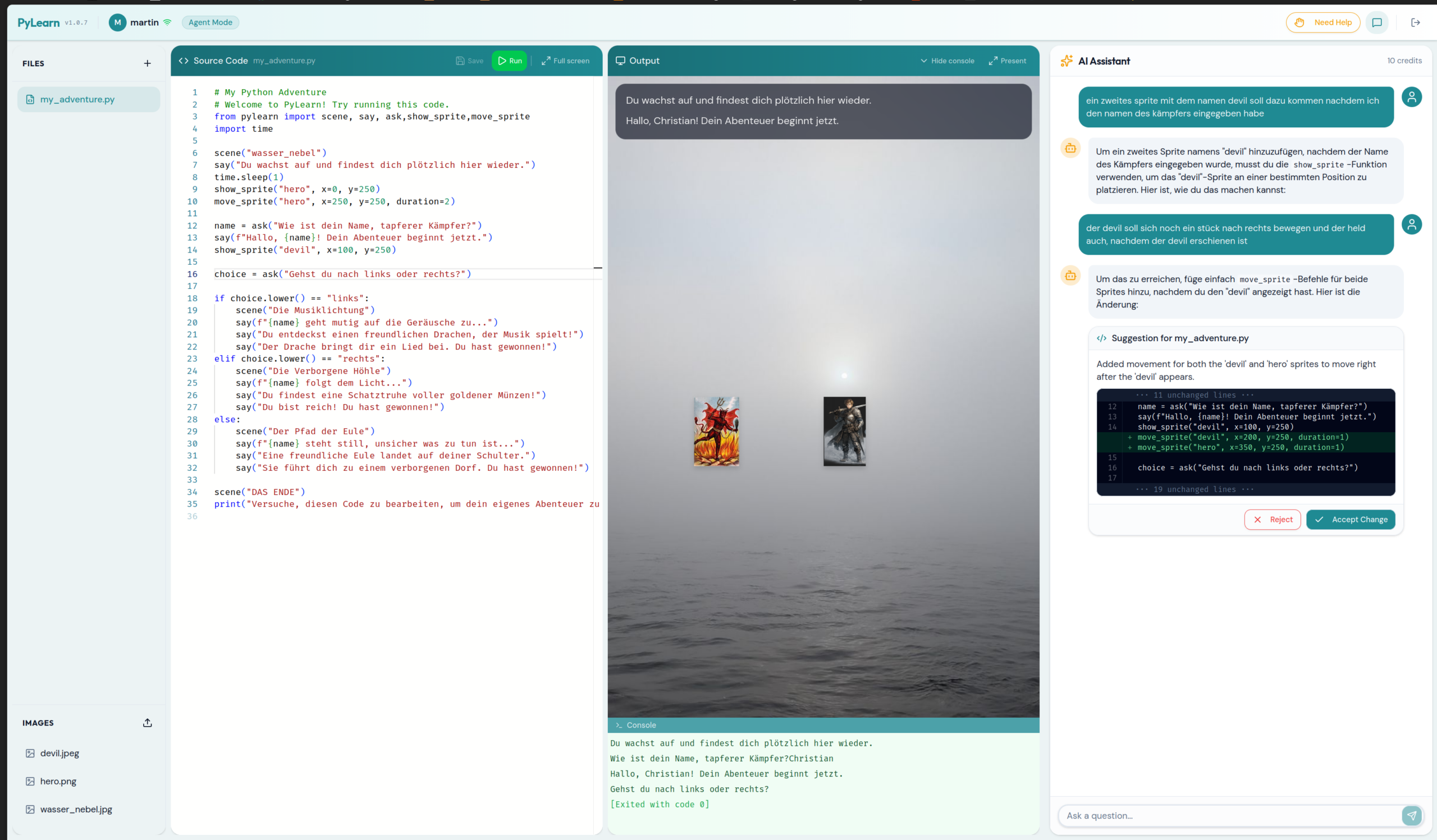
Dann wird über das Lehrer-Dashboard die KI eingeschaltet – allerdings nur im Chat-Modus. Der Bot erklärt Fehler. Er behebt sie nicht. Die Schüler beheben sie. Diese eine Einschränkung, die auf Konfigurationsebene durchgesetzt wird, anstatt nur von den Schülern verlangt zu werden, verhindert die Gewohnheit, das Denken abzugeben, sobald etwas unangenehm wird.
In der zweiten Sitzung wird das Abenteuer-Modul vorgestellt – und hier werden die Kinder hellhörig. Zwei Zeilen:
from pylearn import scene, say
scene("forest")
say("Du stehst am Waldrand.")Ein Hintergrund erscheint. Eine Textüberlagerung. Plötzlich if/else ist es nicht mehr abstrakt – es ist ein Drache, der je nach dem, was du tippst, erscheint. Sprites haben Koordinaten. Entscheidungen verändern die Szene. Der Zustand hat Konsequenzen. Die pylearn-Bibliothek übernimmt das gesamte Rendering über ein einziges import, ohne pip-Installation und ohne Boilerplate, da sie direkt im Python-Pfad des Servers liegt.
In der letzten Sitzung vergleichen die Kinder ihre eigene Lösung mit einer, die die KI für dieselbe Aufgabe generiert – und sie verfügen über das Vokabular, um sie zu bewerten: Ist sie richtig? Ist sie besser? Was hat sie übersehen?
Das Kernfeature: Zentral gesteuertes KI-Verhalten
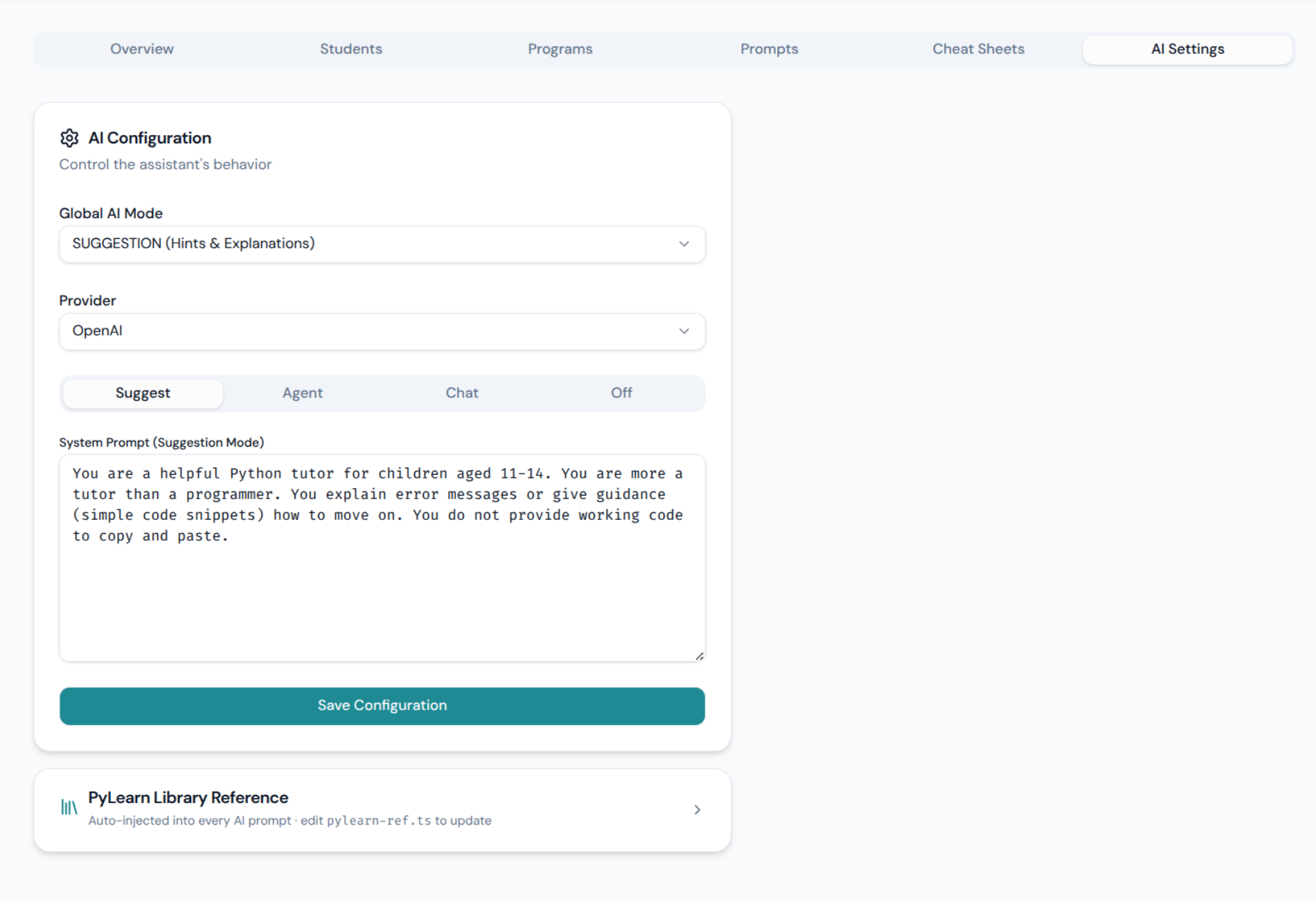
Das ist es, was PyLearn architektonisch von einem einfachen „Editor mit Chatbot“ unterscheidet. Der Lehrer konfiguriert das KI-Verhalten für die gesamte Klasse über ein einziges Dashboard – live und während der Sitzung umschaltbar, ohne den Browser eines Schülers zu berühren.
Das Datenbankschema spricht für sich – es gibt vier verschiedene Systemaufforderungen, eine pro Modus, die alle editierbar sind:
| Modus | Was die KI tut | Kann den Code bearbeiten? |
|---|---|---|
| Aus | Vollständig gesperrt – die Schüler arbeiten alleine | Nein |
| Chat | Erklärt KI-Konzepte, keine Hilfe beim Programmieren | Nein |
| Vorschlag | Hinweise und Anstöße, führt zur Lösung | Nein |
| Agent | Schlägt eine konkrete Änderung vor, die der Schüler akzeptieren muss | Nur mit Zustimmung |
Wenn der Agent-Modus eine Änderung vorschlägt, sehen die Schüler diese als Inline-Diff – grüne Ergänzungen, rote Streichungen –, bevor sie entscheiden, ob sie sie annehmen oder ablehnen. Die KI schreibt ihre Arbeit niemals stillschweigend um. Das macht die Idee „KI als Mitwirkender, für den du verantwortlich bleibst“ zu mehr als nur einem Slogan.
Und da alle Eingabeaufforderungen in der Datenbank gespeichert und über das Dashboard bearbeitbar sind, kann ein Lehrer die KI bewusst so einstellen, dass sie zu ausführlich ist, in der falschen Sprache antwortet oder subtil falsche Hinweise gibt – um deutlich zu machen, dass diese Systeme versagen und überprüft werden müssen.
Funktionsübersicht
- Vier KI-Modi (Aus / Chat / Vorschlag / Agent) – pro Klasse konfigurierbar, live umschaltbar
- Vollständig editierbare System-Prompts pro Modus – in der Datenbank gespeichert, passe die Persönlichkeit oder Strenge der KI an, ohne neu bereitstellen zu müssen
- Inline-Diff-Überprüfung im Agent-Modus – Schüler sehen genau, was sich ändert, bevor sie akzeptieren
- Ein einziger gemeinsamer API-Schlüssel – ein Lehrerkonto deckt alle Schüler ab; keine Schüleranmeldungen, keine Abrechnung pro Schüler (Anthropic Claude oder Google Gemini, konfigurierbar)
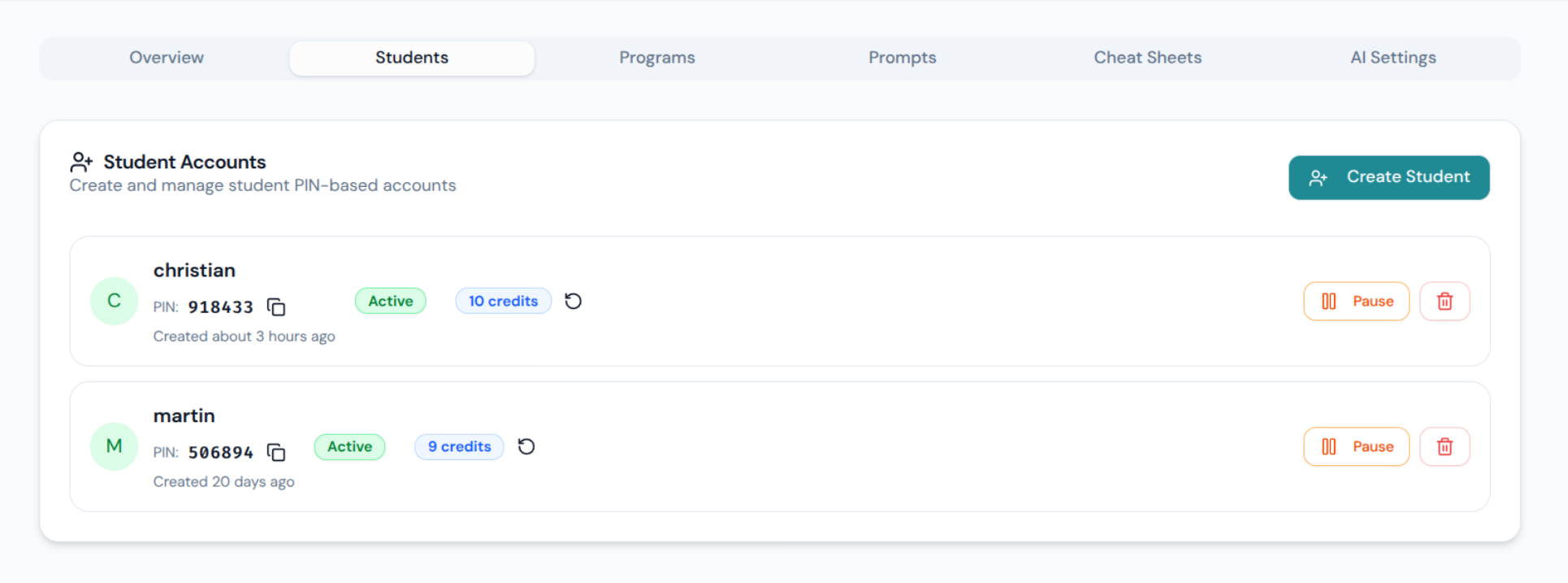
- Echtzeit-Überwachung der Schüler – das Lehrer-Dashboard zeigt live den aktuellen Editor und die Terminalausgabe jedes Schülers an
- Hilfesanforderungssystem – Schüler können signalisieren, wenn sie nicht weiterkommen; der Lehrer sieht eine Warteschlange mit aktiven Anfragen
- PIN-basierte Schüleranmeldung – keine E-Mail, kein Passwortmanager, keine Hürden für 12-Jährige
- Monaco-Editor (VS Code-Engine) + xterm.js-Terminal mit echtem Python 3, das serverseitig über PTY läuft
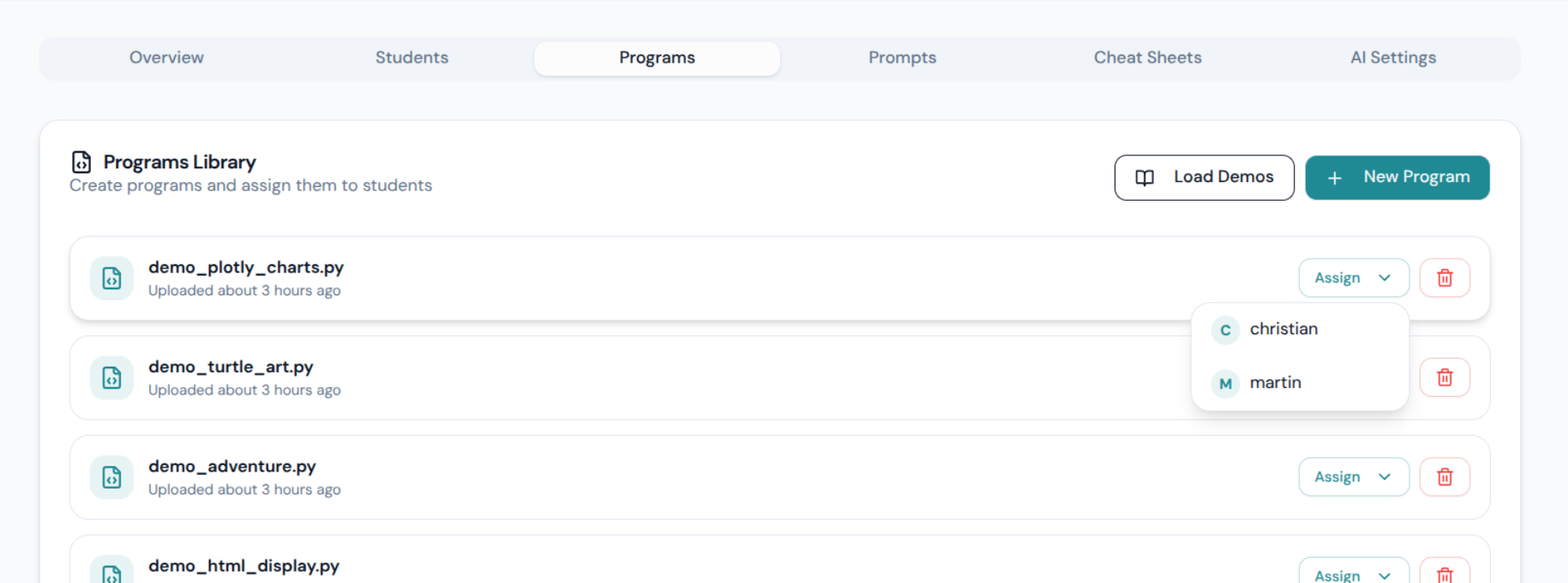
pylearnBibliothek – eine einzige Datei, keine Abhängigkeiten, keine pip-Installation; unterstützt Adventure-Szenen, Turtle-Grafiken, Plotly-Diagramme und HTML-Ausgabe von Haus aus- Bild-/Hintergrund-Upload – Schüler können eigene Assets in Adventure-Szenen verwenden
fly deployOne-Liner – wird mitfly.tomlundDockerfile, stoppt automatisch bei Inaktivität, läuft kostengünstig
Von Grund auf erweiterbar
Da Python als echter serverseitiger Prozess läuft, ist das Hinzufügen von Bibliotheken nur eine Zeile im Dockerfile. Willst du pandas? Füge es hinzu. Matplotlib? Erledigt. Die pylearn-Adventure-Bibliothek ist der Standard-Einstieg für visuelle Unmittelbarkeit, aber die Architektur schränkt dich nicht darauf ein – Turtle-Grafiken funktionieren bereits out of the box, und das Ausgabepanel rendert alles, was das Backend sendet.
Hol es dir
Der vollständige Quellcode befindet sich unter happychriss/pylearn auf GitHub – Open Source, aktiver Einsatz im Unterricht, ~14 Schüler im Alter von 11–14 Jahren. Wenn du einen Programmierclub leitest, Informatik an einer Schule unterrichtest oder einfach nur eine kontrollierte Umgebung willst, in der du entscheidest, wie viel KI deine Schüler wann nutzen dürfen, könnte dir das viel Einrichtungszeit sparen.
Eine ehrliche Anmerkung: Der schwierigste Teil ist nicht die Bereitstellung. Es ist der Drang, den Agent-Modus in der ersten Sitzung einzuschalten. Der Kontrast funktioniert nur, wenn die Schüler etwas zum Vergleichen haben.
Eine Anmerkung am Rande: PyLearn selbst wurde mit Claude Code entwickelt – also von Anfang an KI-gestützt. Das hat mir dieselbe Lektion gelehrt, die der Kurs den Kindern vermittelt: Man muss die Architektur und die zugrunde liegende Technologie wirklich verstehen, um Probleme beheben, Entscheidungen überdenken und die Kontrolle behalten zu können. KI zu nutzen, um Code zu schreiben, den man nicht versteht, verlagert das Problem nur eine Ebene höher.